Cuando estaba estudiando la carrera de ingeniería en mecatrónica, estuve siempre rodeado de compañeros que cuestionaban la necesidad de aprender cálculo, que juraban que "en la industria nunca se usa nada de eso".
Compañeros que justificaban sus bajas calificaciones en las materias más demandantes diciendo que todo eso ya lo hace un software.
Hace un par de meses, en el trabajo, unos ingenieros estaban literalmente tratando de recordar lo que dice el teorema de Stokes para poder dar una estimación de un flujo que cambiaría la densidad de otra cosa, cambiando el gradiente de temperatura. La simulación numérica tomaría días en programar y horas en converger. Ellos necesitaban la aproximación ya.
Eso me gustó. Me hizo recordar todo lo que decían mis compañeros y finalmente pude probarlos equivocados. En las aplicaciones correctas, en el nivel correcto, la ingeniería requiere más que solo conectar cables y soldar placas. Requiere más que leer tablas o seguir manuales.
En las últimas semanas diseñé un filtro digital. Para hacer eso tuve que recordar mis clases de control. Tuve que obtener la transformada de Laplace de una función, obtener su función de transferencia, usar un filtro pasa bajas analógico, usar la transformada Z, y verificar su estabilidad.
Ver esas crucecitas dentro del círculo unitario (lo que indica que el filtro es estable) me causó una sonrisa que no pude disimular.
Implementé el filtro en un código computacional. Lo simulé y evalué su estabilidad en frecuencia.
Lo presenté con un montón de expertos. Me hicieron preguntas, me pidieron un montón de simulaciones en lazo cerrado, en lazo abierto, me pidieron que revisara un montón de documentos y finalmente lo aceptaron.
Ese filtrito que salió usando todo eso que mis compañeros dijeron que no se usa en la industria estará en unos meses montado en un avión. Volando. Llevando personas de un lugar a otro.
Seguramente mis compañeros están en otras empresas, haciendo dibujos en la computadora, o haciendo itinerarios o arreando técnicos para que solden placas en tarjetas electrónicas o midiendo piezas. Seguramente sin usar todo eso que vimos en la carrera. Seguramente ganando más que yo. Pero hoy soy un ingeniero. Uno de verdad. Eso me hace feliz.
jueves, octubre 29, 2015
lunes, diciembre 22, 2014
Centésimo sexagésimo quinto - Lo que yo esperaba -
En julio del 2003 (cuando estaba por entrar a la universidad), le dije a mis padres que quería estudiar la carrera de mecatrónica. Esto los tomó por sorpresa porque había dedicado mis últimos tres años a decir que quería estudiar Ingeniería en Sistemas Computacionales (oh, qué joven y estúpido era).
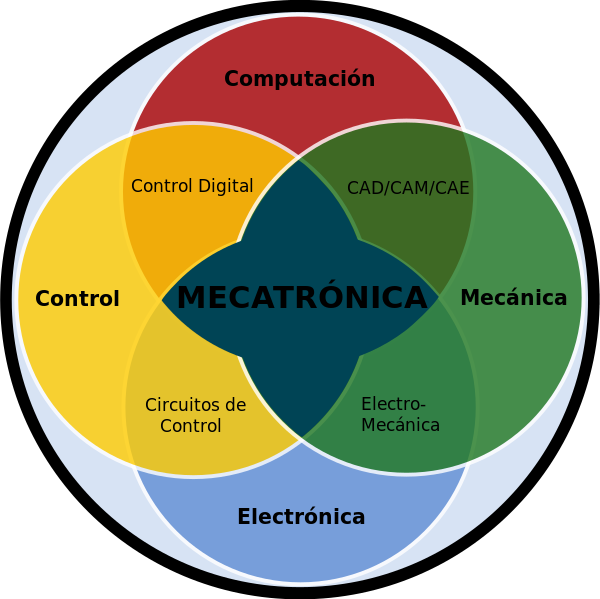
Ninguno de mis padres sabía siquiera qué es la mecatrónica. Cuando les expliqué - casi hasta con el famoso diagrama de Venn - de lo que era mecatrónica, le pregunté a mi madre que qué le parecía la idea. No como si fuera a cambiar mi decisión, pero sí buscando su bendición.
Ella me dijo que le parecía bien, que como yo quisiera y la chingada.
Se me ocurrió preguntarle qué "cosa le gustaría que le construyera". Ella me dijo, no sé si incrédula, no sé si condescendientemente:
Cuando se lo di, mientras recreaba la historia y le recordaba sus palabras, yo esperaba un abrazo sincero, un agradecimiento no por el objeto, sino por no olvidar la promesa hecha de un hijo a una madre.
Lo que obtuve fue un:
Ninguno de mis padres sabía siquiera qué es la mecatrónica. Cuando les expliqué - casi hasta con el famoso diagrama de Venn - de lo que era mecatrónica, le pregunté a mi madre que qué le parecía la idea. No como si fuera a cambiar mi decisión, pero sí buscando su bendición.
Ella me dijo que le parecía bien, que como yo quisiera y la chingada.
Se me ocurrió preguntarle qué "cosa le gustaría que le construyera". Ella me dijo, no sé si incrédula, no sé si condescendientemente:
"Un robot que trapée".Ayer, después de 11 años finalmente cumplí mi promesa. Mi madre tiene ahora un robot que trapea.
Cuando se lo di, mientras recreaba la historia y le recordaba sus palabras, yo esperaba un abrazo sincero, un agradecimiento no por el objeto, sino por no olvidar la promesa hecha de un hijo a una madre.
Lo que obtuve fue un:
"Te dije que quería un robot que limpiara la cocina".
viernes, marzo 28, 2014
Centésimo sexagésimo cuarto - Baño de hombres -
Saludos, querido y teórico lector. Por razones que a nadie interesan y a menos importan, he decidido asistir a un gimnasio. Llevo un par de semanas asistiendo religiosamente todos los días de 06:00 a 07:00 hrs. Dejaré para otra ocasión mis comentarios en cómo me he estado matando y no he visto el mínimo resultado siquiera, para hablar de un tema mucho más peculiar... las regaderas.
Sin más, te presento:
Como llegamos bastante temprano al gimnasio, todos llegamos con una pinche cara de desvelados que parece más de muerto. Muchos ni se toman la molestia de enjuagarse la cara antes de salir de sus casas. Después de más o menos una hora de sudar como mineros nos encontramos todavía en un estado más deplorable que cuando llegamos, pero eso sí, pujando como si estuviéramos pariendo mientras levantamos pesas para apantallar a las pocas mujeres que asisten al gimnasio.
Cuando de plano tenemos que dejar el homoerotismo de ver a un sudoroso sujeto jalando poleas tenemos que irnos directito a las regaderas.
Las regaderas son - afortunadamente - privadas y cada una tiene su respectiva puerta, así que tampoco estamos como en la cárcel. Es precisamente esa idea de pudor la que genera toda clase de reacciones en el lugar. El lugar donde se encuentran las regaderas no es particularmente grande, aunque sí tiene unas 10 regaderas. Sin embargo, el área "comunitaria" donde dejas tu maleta consta únicamente de un par de bancas (bastante pegadas entre ellas).
Cuando tienes la fortuna de llegar temprano a las regaderas, puedes elegir el lugar donde vas a sentarte para sacar tu ropa, tu toalla y tus sandalias de baño. Los menos afortunados tiene que sentarse entre dos vatos al lado y uno en frente. Mientras estás quitándote los tenis y las calcetas y esculcas en tu maleta buscando tu ropa interior no puedes evitar mirar al resto de los presentes haciendo lo mismo, preguntádote cómo es que alguien puede usar ropa interior tan pinche.
Los menos pudorosos comienzan a desvestirse en el área común, hasta quedar únicamente con los bóxers (o calzoncillos). Luego se van a las regaderas con nada más que una toalla y su jabón.
Después de un prolijo aseo, en el que cuidas el mínimo movimiento so pena de mojar accidentalmente la ropa que dejaste colgando en el perchero instalado en la puerta, procedes a malabarear para vestirte sin que tus pantalones toquen el suelo mojado. Sales con tu camisa planchada, tus pantalones mojados inevitablemente porque te falta habilidad para evitarlo y más despeinado que como llegaste.
Al llegar al área común, te sientas mientras buscas tus calcetines, te secas concienzudamente los pies y mientras te dispones a ponerte desodorante llega uno de esos sujetos a los que no les da pena nada, paseándose únicamente con una toalla en la cintura.
No entraré en detalles de la fisonomía del sujeto, pero cada que alguien sale de esa manera de la regadera, inmediatamente todos dirigimos nuestras miradas al piso. Tú sabes. Nadie quiere ser "cachado" observando el abultado vientre de otro güey.
Al tiempo que el sujeto en toalla llega al área común y saca sus calzoncillos para ponérselos (eso sí, muy hábilmente) por debajo de la toalla, tú vas terminando de vestirte por completo. Un nuevo sujeto entra al baño y como el de la toalla está algo inclinado para poder buscar sus cosas, nadie se mueve. No vaya a ser que camines y pases demasiado cerca del güey desnudo empinado.
Ya que puedes pasar y vas saliendo te despides de todos con un leve movimiento de cabeza como diciendo "Sale", pero en realidad vas pensando: "seguramente la tengo más grande". Ellos responden con un leve movimiento de cabeza como diciendo "órale", pero pensando: "seguramente la tengo más grande".
Sin más, te presento:
Regaderas para hombres
Is anyone here who can swear before God he has nothing to fear, nothing to hide?
Como llegamos bastante temprano al gimnasio, todos llegamos con una pinche cara de desvelados que parece más de muerto. Muchos ni se toman la molestia de enjuagarse la cara antes de salir de sus casas. Después de más o menos una hora de sudar como mineros nos encontramos todavía en un estado más deplorable que cuando llegamos, pero eso sí, pujando como si estuviéramos pariendo mientras levantamos pesas para apantallar a las pocas mujeres que asisten al gimnasio.
Cuando de plano tenemos que dejar el homoerotismo de ver a un sudoroso sujeto jalando poleas tenemos que irnos directito a las regaderas.
Las regaderas son - afortunadamente - privadas y cada una tiene su respectiva puerta, así que tampoco estamos como en la cárcel. Es precisamente esa idea de pudor la que genera toda clase de reacciones en el lugar. El lugar donde se encuentran las regaderas no es particularmente grande, aunque sí tiene unas 10 regaderas. Sin embargo, el área "comunitaria" donde dejas tu maleta consta únicamente de un par de bancas (bastante pegadas entre ellas).
Cuando tienes la fortuna de llegar temprano a las regaderas, puedes elegir el lugar donde vas a sentarte para sacar tu ropa, tu toalla y tus sandalias de baño. Los menos afortunados tiene que sentarse entre dos vatos al lado y uno en frente. Mientras estás quitándote los tenis y las calcetas y esculcas en tu maleta buscando tu ropa interior no puedes evitar mirar al resto de los presentes haciendo lo mismo, preguntádote cómo es que alguien puede usar ropa interior tan pinche.
Los menos pudorosos comienzan a desvestirse en el área común, hasta quedar únicamente con los bóxers (o calzoncillos). Luego se van a las regaderas con nada más que una toalla y su jabón.
Después de un prolijo aseo, en el que cuidas el mínimo movimiento so pena de mojar accidentalmente la ropa que dejaste colgando en el perchero instalado en la puerta, procedes a malabarear para vestirte sin que tus pantalones toquen el suelo mojado. Sales con tu camisa planchada, tus pantalones mojados inevitablemente porque te falta habilidad para evitarlo y más despeinado que como llegaste.
Al llegar al área común, te sientas mientras buscas tus calcetines, te secas concienzudamente los pies y mientras te dispones a ponerte desodorante llega uno de esos sujetos a los que no les da pena nada, paseándose únicamente con una toalla en la cintura.
No entraré en detalles de la fisonomía del sujeto, pero cada que alguien sale de esa manera de la regadera, inmediatamente todos dirigimos nuestras miradas al piso. Tú sabes. Nadie quiere ser "cachado" observando el abultado vientre de otro güey.
Al tiempo que el sujeto en toalla llega al área común y saca sus calzoncillos para ponérselos (eso sí, muy hábilmente) por debajo de la toalla, tú vas terminando de vestirte por completo. Un nuevo sujeto entra al baño y como el de la toalla está algo inclinado para poder buscar sus cosas, nadie se mueve. No vaya a ser que camines y pases demasiado cerca del güey desnudo empinado.
Ya que puedes pasar y vas saliendo te despides de todos con un leve movimiento de cabeza como diciendo "Sale", pero en realidad vas pensando: "seguramente la tengo más grande". Ellos responden con un leve movimiento de cabeza como diciendo "órale", pero pensando: "seguramente la tengo más grande".
domingo, enero 19, 2014
Centésimo sexagésimo tercero - solo -
A veces, sólo a veces, cuando termino de ver un episodio particularmente bueno de una serie de TV (por lo regular sitcoms), después de apagar la computadora y la luz, recuerdo una escena graciosa y me río los tres pasos entre el interruptor de la luz y mi cama. Y mientras me río y caigo pesadamente sobre la cama pienso: voy a morir solo.
domingo, agosto 18, 2013
Centésimo sexagésimo segundo - ¿Dónde estoy? -
Favor de poner esta canción mientras lees el post:
Hacía mucho tiempo que no posteaba.
Hacía mucho tiempo que no sentía esa necesidad imperiosa de escribir. Me da gusto tener algo para escribir aquí finalmente, aunque sea un post pequeño y lleno de frases vagas.
Desde hace casi dos meses tengo un empleo nuevo. Un empleo interesante en el que estoy aprendiendo muchas cosas y en el que si todo sale bien, podré avanzar bastante. Un empleo en el que me siento a gusto. Un empleo que tiene muchas cosas que no cualquier ingeniero podría desarrollar y otras muchas que en ocasiones me hace sentir más como una secretaria que como un ingeniero.
Pero no me encuentro en donde yo quería. A esta edad yo debería estar terminando mi doctorado. Mi empleo actual tiene muchas cosas buenas, y no gano mal. Y sin duda podría verme trabajando ahí por mucho mucho tiempo. Pero no es un doctorado. No es esa oportunidad de llevar el conocimiento un pasito más allá. No es ese reto incansable y maravilloso de ser el mejor del mundo en tu tema. Y sobre todo, nada de lo que pueda llegar a hacer en la compañía podrá ser compartido con el mundo, permitiendo que nueva tecnología se base en el trabajo que hice.
Estoy en una posición bastante incómoda. Yo quiero mi doctorado. Pero las tantas situaciones por las que ha pasado mi familia me han impedido siquiera comenzar con ese proyecto. Llegará un momento en el que tendré que elegir entre perder lo que pueda conseguir en la compañía para dirigirme al siempre inseguro destino de un doctorado o dejar a un lado el sueño de mi vida para mantenerme con cierta seguridad laboral, financiera. Cuando llegue el momento de elegir, espero que las situaciones en mi casa hayan mejorado de alguna manera. Porque de lo contrario, la posibilidad de un doctorado es más remota.
De la misma forma, me encuentro en un punto nuevo para mí en lo que se refiere a la parte personal. Siempre pensé que a esta edad estaría en una relación estable y saludable que algún día no particularmente lejano desembocara en matrimonio. Pero no estoy ni cerca de eso.
No estoy sufriendo una crisis de la mediana edad o de los treinta años. La edad no me resulta tan importante como el hecho de saber que pronto tendré que enfrentarme a situaciones que definirán el resto de mi vida. La mayoría de las personas se enfrentan a situaciones en las que no saben el resultado. Y al ser mayores se ven al pasado sin más remordimientos que las cosas que no hicieron, conocedores del camino que tomaron. Yo sé perfectamente qué dejo, que dejé o qué dejaré. Si algún día veo al pasado tendré el remordimiento no solo de no haber tomado la otra decisión, sino de saber que mi mejor cálculo y mi racionamiento fallaron cuando más lo necesitaba.
No tengo miedo a lo que vendrá. Pero no quiero terminar mi vida sabiendo que me decidí por la mediocridad.
Hacía mucho tiempo que no posteaba.
Hacía mucho tiempo que no sentía esa necesidad imperiosa de escribir. Me da gusto tener algo para escribir aquí finalmente, aunque sea un post pequeño y lleno de frases vagas.
Desde hace casi dos meses tengo un empleo nuevo. Un empleo interesante en el que estoy aprendiendo muchas cosas y en el que si todo sale bien, podré avanzar bastante. Un empleo en el que me siento a gusto. Un empleo que tiene muchas cosas que no cualquier ingeniero podría desarrollar y otras muchas que en ocasiones me hace sentir más como una secretaria que como un ingeniero.
Pero no me encuentro en donde yo quería. A esta edad yo debería estar terminando mi doctorado. Mi empleo actual tiene muchas cosas buenas, y no gano mal. Y sin duda podría verme trabajando ahí por mucho mucho tiempo. Pero no es un doctorado. No es esa oportunidad de llevar el conocimiento un pasito más allá. No es ese reto incansable y maravilloso de ser el mejor del mundo en tu tema. Y sobre todo, nada de lo que pueda llegar a hacer en la compañía podrá ser compartido con el mundo, permitiendo que nueva tecnología se base en el trabajo que hice.
Estoy en una posición bastante incómoda. Yo quiero mi doctorado. Pero las tantas situaciones por las que ha pasado mi familia me han impedido siquiera comenzar con ese proyecto. Llegará un momento en el que tendré que elegir entre perder lo que pueda conseguir en la compañía para dirigirme al siempre inseguro destino de un doctorado o dejar a un lado el sueño de mi vida para mantenerme con cierta seguridad laboral, financiera. Cuando llegue el momento de elegir, espero que las situaciones en mi casa hayan mejorado de alguna manera. Porque de lo contrario, la posibilidad de un doctorado es más remota.
De la misma forma, me encuentro en un punto nuevo para mí en lo que se refiere a la parte personal. Siempre pensé que a esta edad estaría en una relación estable y saludable que algún día no particularmente lejano desembocara en matrimonio. Pero no estoy ni cerca de eso.
No estoy sufriendo una crisis de la mediana edad o de los treinta años. La edad no me resulta tan importante como el hecho de saber que pronto tendré que enfrentarme a situaciones que definirán el resto de mi vida. La mayoría de las personas se enfrentan a situaciones en las que no saben el resultado. Y al ser mayores se ven al pasado sin más remordimientos que las cosas que no hicieron, conocedores del camino que tomaron. Yo sé perfectamente qué dejo, que dejé o qué dejaré. Si algún día veo al pasado tendré el remordimiento no solo de no haber tomado la otra decisión, sino de saber que mi mejor cálculo y mi racionamiento fallaron cuando más lo necesitaba.
No tengo miedo a lo que vendrá. Pero no quiero terminar mi vida sabiendo que me decidí por la mediocridad.
miércoles, febrero 20, 2013
Centésimo sexagésimo primero - Entrevista -
Ayer tuve una entrevista para un posible trabajo. Un trabajo excelente, demandante, interesante, en el que aprendería muchísimo y sobre todo, me desempeñaría en una de las áreas de mi carrera que más me gustan. Un área que ciertamente no muchos ingenieros podrían desarrollar bien.
Y me fue pésimo.
Pero en serio pésimo.
La entrevista ni siquiera fue técnica, pero yo estaba distraído, nervioso, divagando. Respondía con rapidez, pero con indecisión. Respondí con sinceridad si no sabía pero mostré sin quererlo una seriedad que más parecía indiferencia.
Conceptos sencillos chocaban en mi mente preocupándome por decidir si querían la respuesta sencilla, la respuesta difícil, la respuesta de un ingeniero o de un M. C. No sabía si querían que lo explicara como a un niño o como a un experto.
Yo estaba preparado para preguntas técnicas, para preguntas que hicieran sobresalir al mejor ingeniero. Y si las hubieran hecho, seguramente yo habría destacado. Sin embargo, perdí en las preguntas que destacan a la mejor persona.
Y me fue pésimo.
Pero en serio pésimo.
La entrevista ni siquiera fue técnica, pero yo estaba distraído, nervioso, divagando. Respondía con rapidez, pero con indecisión. Respondí con sinceridad si no sabía pero mostré sin quererlo una seriedad que más parecía indiferencia.
Conceptos sencillos chocaban en mi mente preocupándome por decidir si querían la respuesta sencilla, la respuesta difícil, la respuesta de un ingeniero o de un M. C. No sabía si querían que lo explicara como a un niño o como a un experto.
Yo estaba preparado para preguntas técnicas, para preguntas que hicieran sobresalir al mejor ingeniero. Y si las hubieran hecho, seguramente yo habría destacado. Sin embargo, perdí en las preguntas que destacan a la mejor persona.
viernes, noviembre 16, 2012
Centésimo cexagésimo - Buen Fin -
Hoy comenzó el buen fin.
Y a diferencia de lo que yo esperaba - descuentos importantes en electrónica, sobre todo TV - lo que las tiendas te ofrecen son "pagos a meses".
En realidad suena bastante atractivo. Si pagas con tarjeta de crédito, te dan hasta 24 meses para pagar y en lugar de pagar $10000.00 de un chingazo, pagas como $500.00 al mes. ¿O no es así?
Estrictamente hablando, sí es así. En 24 meses terminas de pagar la TV, pero también pagas un puterísimo de intereses. Mucho más, querido y teórico lector de lo que piensas.
Vamos a hacer algunas matemáticas para ejemplificar.
Cada mes, se tiene la opción de pagar el monto mínimo de la tarjeta de crédito (usualmente, el 2% del balance que se debe). Sin embargo, los bancos cargan intereses sobre ese balance que no has pagado. Entonces, aunque pagues la tarjeta de crédito a tiempo, sigues pagando intereses. Cuando lees "TV a 24 meses sin intereses con tarjeta de crédito" es porque el banco le paga a la tienda (lo que a ti no te genera intereses) pero el banco te cobra a ti y le gana bastante, porque los intereses que te cobra NO son por la TV, sino por el préstamo del banco.
Digamos que has hecho una compra de $5000.00 con tu tarjeta de crédito con un interés anual de 18% y un pago mínimo mensual de 2%. Si únicamente pagas el mínimo cada mes durante un año ¿Cuánto le debes al banco todavía?
Pudes pensar en esto de la siguiente manera:
Al comienzo del mes 0 (cuando te llega el estado de cuenta del mes) supón que debes una cantidad que llamaremos b0.
Cualquier pago que hagas durante ese mes, se deduce del balance. Llamemos al pago que haces en el mes 0, p0. Al comienzo del mes 1, el banco te cobra un interés sobre el nuevo balance. Entonces, si tu interés anual es r, entonces, al comienzo del mes 1, tu nuevo balance es tu anterior balance b0 menos el pago p0 más el interés de este nuevo balance para el mes que está corriendo. El álgebra, esto sería:
$$b_1 = (b_0 - p_0) (1 + \frac{r}{12})$$
En el mes 1, harás otro pago, p1. Este pago tiene que cubrir algo de los intereses, así que no todo se va a pagar tu deuda original. Y entonces, al comienzo del mes 2, tu balance sería:
Y a diferencia de lo que yo esperaba - descuentos importantes en electrónica, sobre todo TV - lo que las tiendas te ofrecen son "pagos a meses".
En realidad suena bastante atractivo. Si pagas con tarjeta de crédito, te dan hasta 24 meses para pagar y en lugar de pagar $10000.00 de un chingazo, pagas como $500.00 al mes. ¿O no es así?
Estrictamente hablando, sí es así. En 24 meses terminas de pagar la TV, pero también pagas un puterísimo de intereses. Mucho más, querido y teórico lector de lo que piensas.
Vamos a hacer algunas matemáticas para ejemplificar.
Cada mes, se tiene la opción de pagar el monto mínimo de la tarjeta de crédito (usualmente, el 2% del balance que se debe). Sin embargo, los bancos cargan intereses sobre ese balance que no has pagado. Entonces, aunque pagues la tarjeta de crédito a tiempo, sigues pagando intereses. Cuando lees "TV a 24 meses sin intereses con tarjeta de crédito" es porque el banco le paga a la tienda (lo que a ti no te genera intereses) pero el banco te cobra a ti y le gana bastante, porque los intereses que te cobra NO son por la TV, sino por el préstamo del banco.
Digamos que has hecho una compra de $5000.00 con tu tarjeta de crédito con un interés anual de 18% y un pago mínimo mensual de 2%. Si únicamente pagas el mínimo cada mes durante un año ¿Cuánto le debes al banco todavía?
Pudes pensar en esto de la siguiente manera:
Al comienzo del mes 0 (cuando te llega el estado de cuenta del mes) supón que debes una cantidad que llamaremos b0.
Cualquier pago que hagas durante ese mes, se deduce del balance. Llamemos al pago que haces en el mes 0, p0. Al comienzo del mes 1, el banco te cobra un interés sobre el nuevo balance. Entonces, si tu interés anual es r, entonces, al comienzo del mes 1, tu nuevo balance es tu anterior balance b0 menos el pago p0 más el interés de este nuevo balance para el mes que está corriendo. El álgebra, esto sería:
$$b_1 = (b_0 - p_0) (1 + \frac{r}{12})$$
En el mes 1, harás otro pago, p1. Este pago tiene que cubrir algo de los intereses, así que no todo se va a pagar tu deuda original. Y entonces, al comienzo del mes 2, tu balance sería:
$$b_2 = (b_1 - p_1) (1 + \frac{r}{12})$$
Si escoges pagar el mínimo cada mes, verás que el interés compuesto reduce tu capacidad de reducir tu deuda.
Si escoges pagar el mínimo cada mes, verás que el interés compuesto reduce tu capacidad de reducir tu deuda.
Para este ejemplo, tendríamos:
Puedes ver que mucho de tu pago se va a cubrir intereses, y si realizas todos los cálculos, verás que después de un año, habrás pagado $1165.63 y sin embargo, todavía le deberás al banco $4691.11 en lo que originalmente era una deuda de $5000.00. ¡Dime si no son chingaderas!
| Mes | Balance | Pago | Interés |
|---|---|---|---|
| 0 | 5000.00 | 100 (= 5000 * 0.02) | 73.50 (= (5000 - 100) * 0.18/12) |
| 1 | 4973.50 (= 5000 - 100 + 73.50) | 99.47 (= 4973.50 * 0.02) | 73.11 (= (4973.50 - 99.47) * 0.18/12) |
Puedes ver que mucho de tu pago se va a cubrir intereses, y si realizas todos los cálculos, verás que después de un año, habrás pagado $1165.63 y sin embargo, todavía le deberás al banco $4691.11 en lo que originalmente era una deuda de $5000.00. ¡Dime si no son chingaderas!
Querido y teórico lector, como ves aunque las tarjetas hacen el paro, son peligrosas. Sobre todo si no las sabemos usar. Yo por eso no tengo tarjeta de crédito y pago en efectivo.
Suscribirse a:
Entradas (Atom)



{kind=link}